
คำนำ
คนเราลืมของเก่าได้เป็นเรื่องปกติ แต่ถ้า AI ลืมล่ะ? จะดีหรือไม่ดี? คำถามนี้กำลังเป็นที่ถกเถียงกันมากในวงการวิจัย AI ปี 2026 — ฝ่ายหนึ่งเชื่อว่า AI ควร "สรุป" ข้อมูลเก่าให้กระชับเพื่อประหยัดพื้นที่ อีกฝ่ายเชื่อว่า AI ควร "เก็บของดิบ" ไว้ทั้งหมดแล้วใช้ระบบค้นหาที่ฉลาดแทน วันนี้เราจะมาเจาะลึกทั้งสองแนวคิด พร้อมบอกว่าอะไรที่ทดสอบแล้วว่าได้ผลดีกว่า
เนื้อหา
ปัญหา: AI "หมดความจำ"
ลองนึกภาพว่าคุณคุยกับ AI มา 3 เดือน — ทักทายทุกวัน ขอคำปรึกษา แชร์เรื่องส่วนตัว — แต่วันหนึ่ง AI บอกว่า "ขอโทษครับ ผมจำอะไรไม่ได้เลย"
นี่ไม่ใช่เรื่องแต่ง — มันเกิดขึ้นจริงกับ Claude Code ที่หลายคนใช้กัน: เมื่อการสนทนายาวเกินไป ระบบจะทำสิ่งที่เรียกว่า "Compaction" — คือการสรุปย่อข้อความทั้งหมดให้สั้นลง แล้วทิ้งของเดิม
ปัญหาที่พบในชีวิตจริง:
ข้อมูลสำคัญจาก 2-4 สัปดาห์ก่อน ยังพอจำได้บ้าง ข้อมูลจากเดือนก่อนหน้า แทบไม่เหลืออะไร ข้อมูลจาก 3 เดือนขึ้นไป หายไปแล้ว แถม ไม่มีทางรู้เลย ว่าอะไร "ร่วง" ไประหว่างการสรุป
แนวคิดที่ 1: สรุปแล้วลบ (Summarization)
นี่คือวิธีที่ AI หลายตัวใช้อยู่ — เหมือนคนอ่านหนังสือแล้วเขียนสรุปแทน
วิธีการ:
- เก็บข้อความโต้ตอบทั้งหมดไว้ก่อน
- เมื่อ "หน่วยความจำ" ใกล้เต็ม → สรุปข้อความเก่า
- ทิ้งข้อความดิบ เก็บแค่สรุป
- ทำงานต่อจากสรุปนั้น
เปรียบเทียบให้เข้าใจง่าย:
เหมือนอ่านนิยาย 100 หน้า แล้วจดสรุปไว้ 1 หน้า → ทิ้งนิยาย พออยากรู้รายละเอียด → ไม่มีให้ดูแล้ว มีแค่สรุป
ผลจาก Mem0 (บริษัทที่ทำระบบความจำ AI):
ใช้วิธี "ดึงข้อมูลสำคัญ" (Fact Extraction) แทนการสรุป ทดสอบกับ LOCOMO (มาตรฐานวัดความจำ AI) ได้ 91.6% เทียบกับการส่งข้อมูลทั้งหมดเข้าไป ได้แค่ 72.9% เทียบกับระบบ Memory ของ OpenAI ได้แค่ 52.9%
สรุป: การดึง "ข้อมูลสำคัญ" แยกเป็นชิ้นๆ ดีกว่าการ "สรุปทั้งก้อน" และดีกว่าการ "ยัดทุกอย่างเข้าไป"
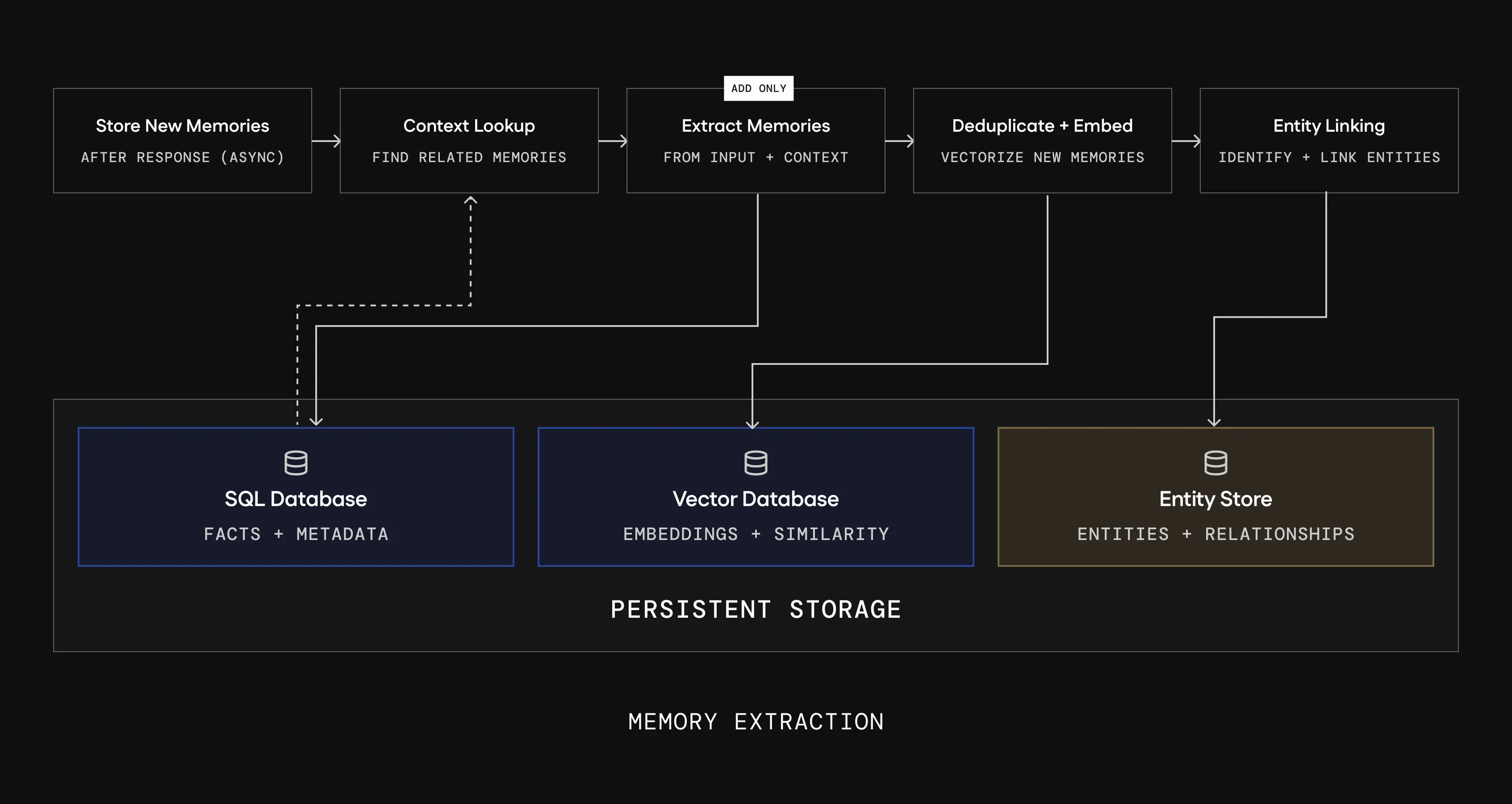
แนวคิดที่ 2: เก็บของดิบ ไม่ทิ้ง (Ground-Truth Preservation)
นี่คือแนวคิดใหม่จากงานวิจัย MemMachine (เมษายน 2026) ที่เสนอวิธีตรงข้ามกันโดยสิ้นเชิง หลักการ: อย่าทิ้งข้อมูลดิบ! เก็บทุกอย่างไว้ แต่ใช้ระบบค้นหาที่ฉลาดมากๆ แทน
สถาปัตยกรรม MemMachine — 3 ชั้น:
| ชั้น | เก็บอะไร | เปรียบเทียบ |
|---|---|---|
| Short-term Memory | บทสนทนาล่าสุด | เหมือน "ความจำระยะสั้น" ของเรา |
| Long-term Episodic Memory | บทสนทนาทั้งหมด (ไม่ทิ้ง!) | เหมือน "ไดอารี่" ที่เขียนทุกวัน |
| Profile Memory | ข้อมูลถาวรเกี่ยวกับผู้ใช้ | เหมือน "บัตรประชาชน" |
จุดเด่นที่ทำให้ MemMachine พิเศษ:
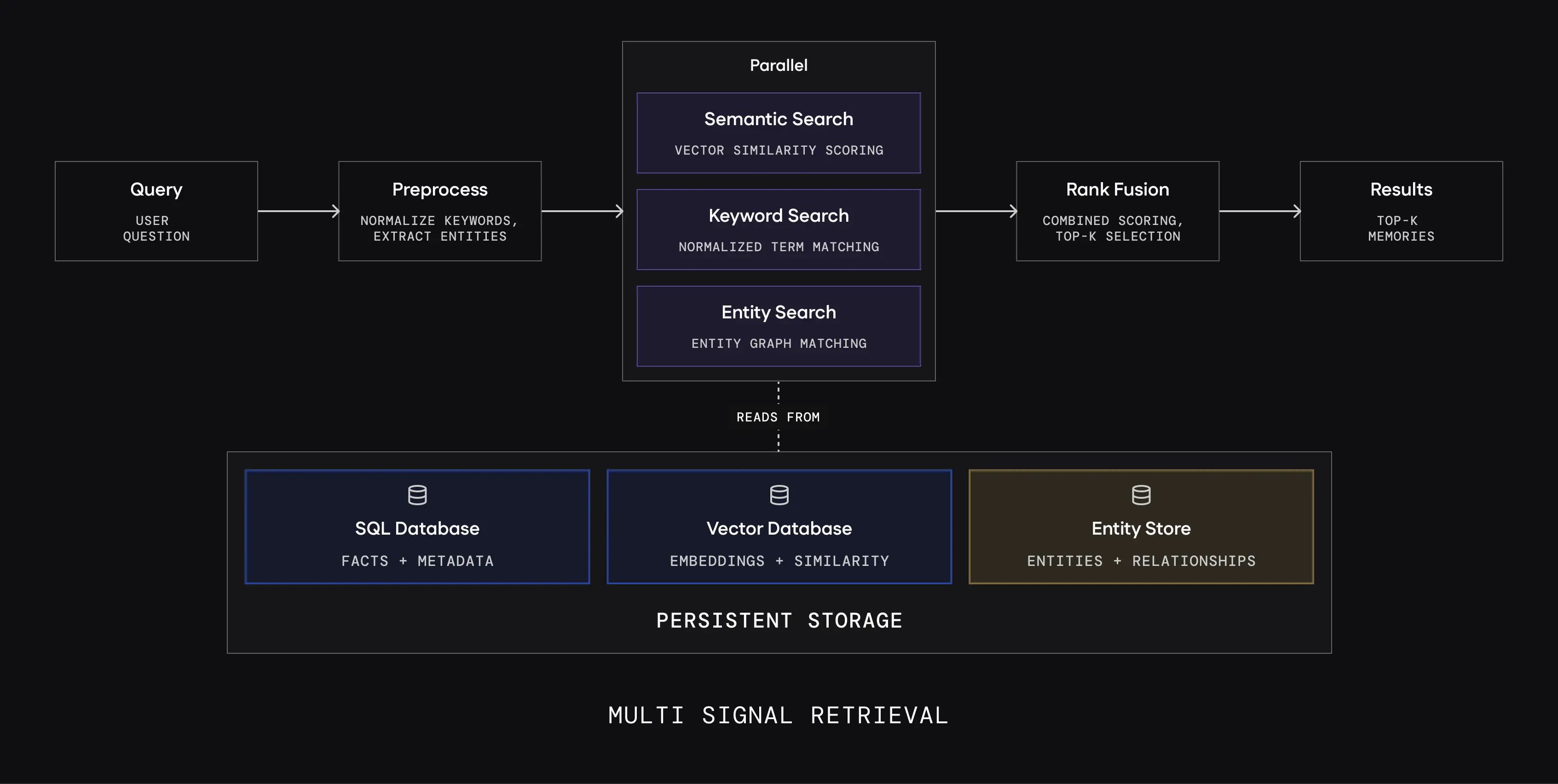
การค้นหาแบบ Adaptive (ปรับตัวเองได้):
MemMachine มี AI ตัวเล็กๆ ที่ทำหน้าที่ "ตัดสินใจว่าจะค้นหาแบบไหน":
| ประเภทคำถาม | วิธีค้นหา | ตัวอย่าง |
|---|---|---|
| คำถามตรงๆ | ค้นหาธรรมดา | "ฉันชื่ออะไร?" |
| คำถามซับซ้อน | แตกเป็นหลายคำถามย่อย ค้นหาพร้อมกัน | "เมื่อเดือนก่อนเราคุยเรื่องอะไรที่เกี่ยวกับโปรเจกต์ X บ้าง?" |
| คำถามที่ต้องตามลุย | ค้นหาเป็นลูกโซ่ | "หลังจากเราตัดสินใจใช้ React แล้ว เกิดอะไรตามมาบ้าง?" |
ผลการทดสอบ MemMachine:
LOCOMO: 91.69% (ใกล้เคียง Mem0 ที่ 91.6%) LongMemEval: 93.0% ใช้ token น้อยกว่า Mem0 ถึง 80%
สรุป: เก็บของดิบไว้ทั้งหมด + ใช้ระบบค้นหาที่ฉลาด = ได้ผลดีพอๆ กับการสกัดข้อมูล แต่ประหยัดกว่า!
เปรียบเทียบทั้ง 2 แนวคิด
| ด้าน | สรุปแล้วลบ | เก็บของดิบ |
|---|---|---|
| การเก็บข้อมูล | สกัดเฉพาะข้อมูลสำคัญ | เก็บทุกอย่าง |
| พื้นที่จัดเก็บ | น้อย (กระชับ) | มาก (แต่ราคาถูกขึ้นทุกวัน) |
| ความแม่นยำ | 91.6% (Mem0) | 91.7% (MemMachine) |
| ต้นทุน | ใช้ token มากกว่า | ใช้ token น้อยกว่า 80% |
| ข้อเสีย | ข้อมูลบางอย่างหายไปถาวร | ต้องมีระบบค้นหาที่ดี |
| ความปลอดภัย | สรุปผิด = เสียข้อมูล | ข้อมูลดิบยังอยู่ ตรวจสอบได้ |
บทเรียนสำคัญ: จากการทดสอบจริง
งานวิจัย MemMachine ได้ข้อสรุปที่น่าสนใจมาก:
"การปรับปรุงระบบค้นหา สำคัญกว่า การปรับปรุงระบบจัดเก็บ"
| สิ่งที่ปรับปรุง | ผลลัพธ์ที่ได้ |
|---|---|
| ปรับความลึกของการค้นหา | +4.2% |
| จัดรูปแบบข้อมูลให้ดีขึ้น | +2.0% |
| ออกแบบ prompt ให้ดีขึ้น | +1.8% |
| แก้ไขอคติในคำถาม | +1.4% |
| ปรับวิธีแบ่งข้อมูลตอนเก็บ | +0.8% |
สังเกตไหมครับ? การ "หาดีๆ" ให้ผลดีกว่าการ "เก็บดีๆ" ถึง 5 เท่า!
อีกบทเรียนน่าทึ่ง: AI เล็ก + คำถามดี > AI ใหญ่
MemMachine ค้นพบว่า: GPT-5-mini (โมเดลเล็ก) + prompt ที่ออกแบบดี = ดีกว่า GPT-5 (โมเดลใหญ่) ถึง 2.6% แปลว่า ไม่จำเป็นต้องใช้ AI ตัวใหญ่แพงๆ ถ้าเราออกแบบระบบค้นหาให้ดีพอ เปรียบเทียบให้เข้าใจ: ใช้นักสืบหน้าใหม่ที่เก่ง (AI เล็ก + ระบบดี) vs ใช้นักสืบอาวุโสที่ไม่มีอุปกรณ์ (AI ใหญ่ + ระบบแย่) นักสืบหน้าใหม่ที่มีกล้องวงจรปิด + ฐานข้อมูล + ทีมสนับสนุน → หาข้อมูลเจอดีกว่า!
สรุป: AI ควร "ลืม" หรือ "จำ"?
จากงานวิจัยทั้งหมด คำตอบคือ "จำ แต่จัดระเบียบให้ดี":
- เก็บข้อมูลดิบไว้ — อย่าทิ้ง! ราคาพื้นที่จัดเก็บถูกลงทุกวัน
- สกัดข้อมูลสำคัญแยกไว้ — เหมือนทำ "ดัชนี" ให้หนังสือ
- ลงทุนที่ระบบค้นหา — ให้ผลดีกว่าลงทุนที่ระบบจัดเก็บ 5 เท่า
- ใช้ AI เล็ก + ระบบดี — ประหยัดกว่าและอาจได้ผลดีกว่าด้วย
- แยก "การทำงาน" กับ "การจัดการความจำ" — อย่าให้ AI ทำทั้งสองอย่างพร้อมกัน
สรุป
คำถาม "AI ควรลืมหรือจำทุกอย่าง?" ไม่ใช่คำถามแบบ "เลือกอย่างใดอย่างหนึ่ง" — คำตอบที่ดีที่สุดคือ "จำทุกอย่าง แต่จัดระเบียบให้ฉลาด" งานวิจัยจากทั้งสองฝ่ายยืนยันตรงกันว่า การมีระบบค้นหาที่ดี สำคัญกว่าการมีระบบจัดเก็บที่สมบูรณ์แบบ และที่น่าประหลาดใจที่สุดคือ AI ตัวเล็กที่ทำงานร่วมกับระบบค้นหาที่ออกแบบดี สามารถเอาชนะ AI ตัวใหญ่ได้ — บทเรียนนี้ไม่ใช่แค่เรื่องเทคโนโลยี แต่เป็นเรื่องของการ "ทำสิ่งที่ถูกต้อง" มากกว่า "ทำสิ่งที่แพงที่สุด"
แหล่งอ้างอิง
• MemMachine — Ground-Truth-Preserving Memory System: https://arxiv.org/abs/2604.04853 (Wang et al., April 2026) • Mem0 Token-Efficient Memory Algorithm: https://mem0.ai/research (Mem0, 2026) • Claude API Compaction: https://platform.claude.com/docs/en/build-with-claude/compaction (Anthropic, 2026) • OpenClaw Memory Management — Live Data, Compaction, and Best Practices: https://mem0.ai/blog/openclaw-memory-management-live-data-compaction-and-best-practices (Mem0 Blog, April 2026) • A Survey on the Memory Mechanism of LLM-based Agents: https://arxiv.org/abs/2404.13501 (Zhang et al., 2024) #AI #MemoryManagement #AIความจำ #Compaction #Mem0 #MemMachine #RetrievalAugmented #KnowledgeManagement #AIResearch #LLM #MemorySystems #เทคโนโลยี #นักพัฒนา #AI_Agent #RAG