
คำนำ
เคยสงสัยไหมว่าทำไมบางที AI ที่คุณคุยด้วยทุกวัน กลับตอบคำถามได้แย่ลงเมื่อเวลาผ่านไป? คำตอบอาจไม่ใช่เพราะ AI โง่ลง แต่เพราะ ข้อมูลในสมองมันยุ่งเหยิงเกินไป — เหมือนคนที่ไม่เคยเก็บห้อง เลยหาของไม่เจอเวลาต้องการ แต่เดือนเมษายน 2026 บริษัท Letta (ผู้สร้าง MemGPT) ได้เปิดตัวแนวคิดที่ปฏิวัติวงการ AI Agent อย่างสมบูรณ์ — ให้ AI "หลับ" เพื่อจัดระเบียบความจำของตัวเอง ขณะเดียวกัน เฟรมเวิร์กยอดนิยมอย่าง LangChain และ LlamaIndex ก็ออกแบบระบบจัดการความจำ AI ที่ต่างแนวทางกันอย่างน่าสนใจ วันนี้เราจะมาเจาะลึกทั้งหมด
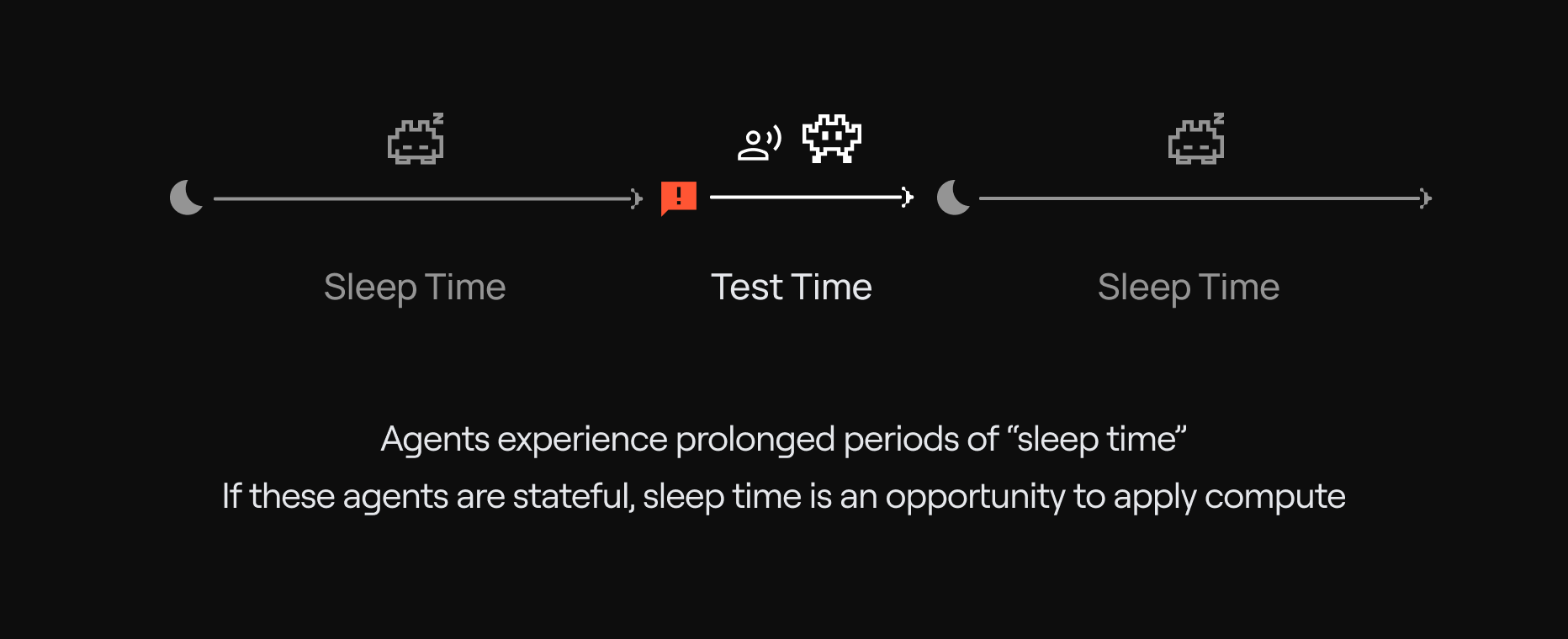
แนวคิดใหม่: Sleep-Time Compute — AI "หลับ" เพื่อคิด
ทำไม AI ต้อง "หลับ"?
ลองนึกภาพว่าคุณเป็นพนักงานบริการลูกค้าที่ต้องคุยกับคนเป็นสิบๆ คนต่อวัน ทุกคนมีคำถามต่างกัน ต้องการข้อมูลต่างกัน — คุณตอบได้ดีใช่ไหม? แต่ถ้าคุณต้อง จดบันทึกทุกคำคุย พร้อมกับ จัดหมวดหมู่ข้อมูล พร้อมกับ ตอบคำถาม ไปพร้อมๆ กันล่ะ? นั่นคือสิ่งที่ AI Agent ทุกตัวต้องเจอทุกวัน

ทีม Letta จึงเสนอแนวคิดที่เรียกว่า "Sleep-Time Compute" — แยก AI Agent ออกเป็น 2 ตัว:
| ตัว | หน้าที่ | ทำอะไรได้บ้าง |
|---|---|---|
| Primary Agent | คุยกับเราเท่านั้น | ตอบคำถาม, เรียกใช้เครื่องมือ, ทำงานตามสั่ง — แต่ไม่มีสิทธิ์แก้ไขความจำตัวเอง |
| Sleep-Time Agent | ทำงานเบื้องหลัง | จัดระเบียบความจำ, สกัดข้อมูลสำคัญ, เชื่อมโยงความรู้ — ทำตอนที่เราไม่ได้คุยกับ AI |
ทำไมถึงฉลาดกว่า?
เหมือนคนเรานั่นแหละครับ — ตอนกลางวันเราทำงาน (Primary Agent) ตอนกลางคืนเรานอนและสมองจัดระเบียบข้อมูล (Sleep-Time Agent)
ข้อดีที่วัดได้:
เร็วขึ้น — Primary Agent ไม่ต้องเสียเวลาจัดความจำตอนคุยกับเรา ตอบได้ทันที แม่นขึ้น — Sleep-Time Agent ใช้เวลานานกว่า + ใช้โมเดลที่แรงกว่า จัดระเบียบได้ดีกว่า ดีขึ้นเรื่อยๆ — แม้เราไม่ได้คุยกับ AI ความจำมันก็ดีขึ้น เพราะ Sleep-Time Agent ทำงานอยู่เบื้องหลัง
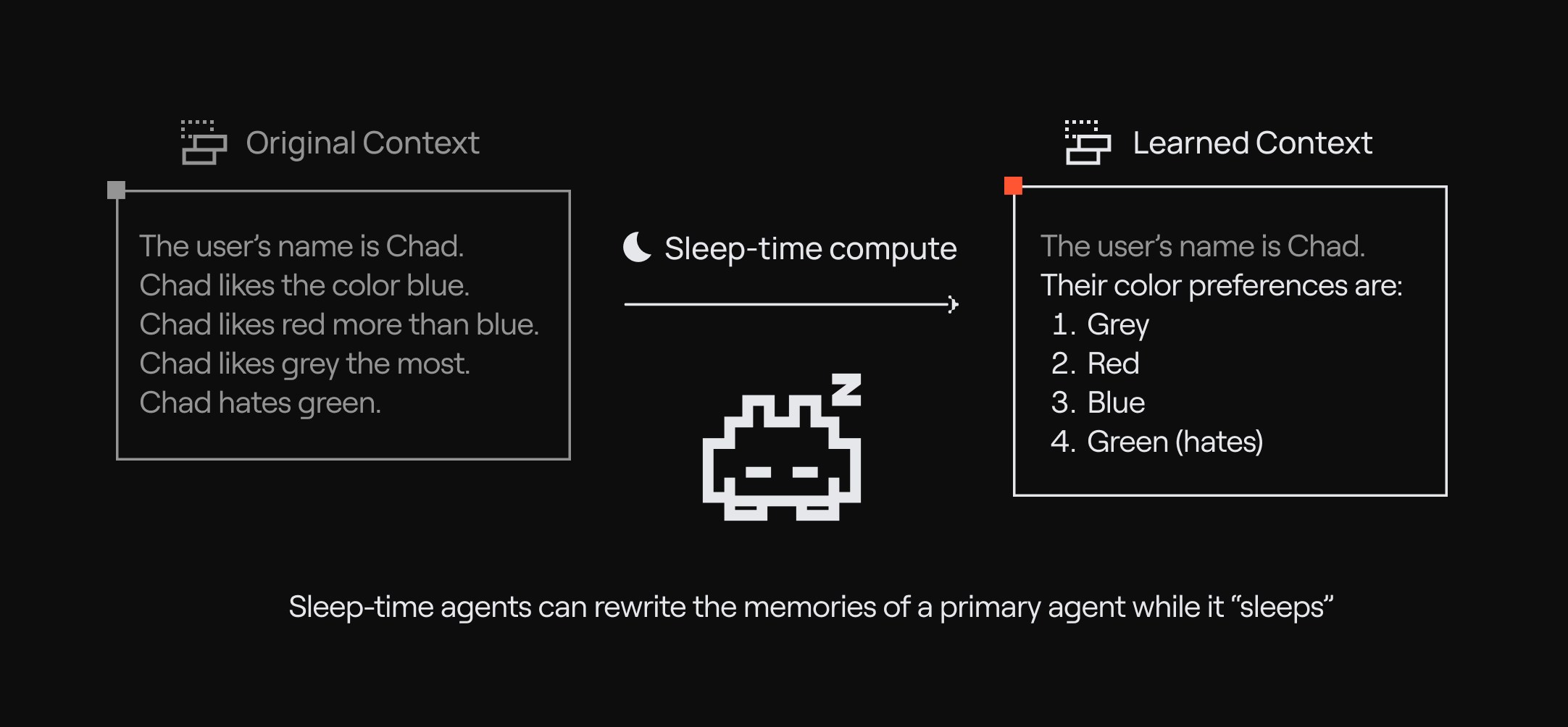
MemFS — AI จัดระเบียบสมองเป็น "โฟลเดอร์" ได้เอง
จาก Key-Value เป็น Filesystem
ก่อนหน้านี้ ระบบความจำ AI ส่วนใหญ่เก็บข้อมูลแบบ "แปะไว้" (key-value) — เหมือนเขียนโน้ตแปะกระดาน ไม่มีหมวดหมู่ ไม่มีโครงสร้าง
Letta เปลี่ยนมาใช้ MemFS (Memory Filesystem) — เก็บความจำเป็น ไฟล์ Markdown ในโฟลเดอร์ เหมือนระบบไฟล์ในคอมพิวเตอร์:
system/ ← อยู่ในสมองตลอดเวลา (เหมือนข้อมูลที่คุณจำขึ้นใจ)
persona.md ← ตัวตนของ AI
dev_workflow/ ← วิธีการทำงาน
humans/ ← ข้อมูลคนที่คุยด้วย
project_a/ ← อ่านเมื่อต้องการ (เหมือนเปิดไฟล์ดู)
frontend.md
backend.md
reflections/ ← บันทึกการสะท้อนคิดจุดเด่น 3 อย่างของ MemFS:
1. Progressive Disclosure (โหลดเฉพาะที่จำเป็น)
ไฟล์ในโฟลเดอร์ system/ → อยู่ในสมอง AI ตลอดเวลา (เหมือนข้อมูลพื้นฐานที่ต้องรู้)
ไฟล์นอก system/ → AI อ่านเฉพาะเมื่อต้องการ (เหมือนเปิดหนังสือดูเฉพาะบทที่อยากรู้)
2. Git-backed Versioning (ทุกการแก้ไขมีประวัติ)
เหมือน Google Docs ที่มี Version History — ทุกครั้งที่ AI แก้ไขความจำ จะมีบันทึกว่าแก้อะไร เมื่อไหร่ ทำไม ถ้า AI แก้ผิด → ย้อนกลับได้ (Rollback) ถ้ามี AI หลายตัวทำงานพร้อมกัน → รวมผลงานได้เหมือนทีมพัฒนาซอฟต์แวร์
3. Memory Skills (ทักษะจัดการความจำ)
Init Skill — AI ตัวใหม่เปิดมาครั้งแรก → สำรวจข้อมูลทั้งหมด → สร้างความจำเริ่มต้นให้เอง Reflection Skill — ทบทวนบทสนทนาล่าสุด → สกัดข้อมูลสำคัญ → เขียนเป็นความจำถาวร Defragmentation Skill — เหมือน "ทำความสะอาดห้อง" — รวมไฟล์ซ้ำ แบ่งไฟล์ใหญ่ จัดโครงสร้างใหม่
LangChain vs LlamaIndex: 2 เฟรมเวิร์กยอดนิยมจัดการความจำ AI ต่างกันอย่างไร?
นอกจาก Letta แล้ว ยังมีอีก 2 เฟรมเวิร์กที่นักพัฒนาทั่วโลกใช้สร้าง AI Agent — LangChain และ LlamaIndex — แต่ละตัวจัดการความจำต่างแนวทางกันอย่างสนใจ
LangChain: จัดการความจำแบบ "ชั้น Middleware"
ลองนึกภาพว่ามี "พนักงานตรวจคัดกรอง" ยืนอยู่ระหว่างความจำกับ AI — ก่อนที่ AI จะได้เห็นข้อมูล พนักงานจะคัดกรองให้ก่อน:
Short-term Memory (ความจำระยะสั้น):
เก็บประวัติการคุยใน session เดียว (เหมือนจำได้ว่าเมื่อกี้คุยอะไรกันไป)
ใช้ checkpointer เก็บข้อมูล (เลือกได้ว่าจะเก็บใน RAM หรือ PostgreSQL)
เมื่อข้อมูลเยอะเกิน → ตัดทอน/สรุป/ลบของเก่าอัตโนมัติ
Long-term Memory (ความจำระยะยาว):
เก็บข้อมูลข้ามหลาย session (เหมือนจำได้ว่าเมื่อเดือนก่อนคุยอะไร)
ใช้ LangGraph Store → จัดเป็นหมวดหมู่ตาม (user_id, topic) — เช่น (user_123, "preferences")
รองรับค้นหาด้วย semantic search
จุดเด่นของ LangChain: ใช้รูปแบบ Middleware — แทรก logic การจัดการความจำระหว่าง AI กับข้อมูล ปรับแต่งได้ง่าย
LlamaIndex: จัดการความจำแบบ "ชั้น Priority"
ในขณะที่ LlamaIndex ใช้แนวคิด "จัดลำดับความสำคัญ" เหมือนจัดโต๊ะทำงาน:
Memory Blocks (กล่องความจำหลายประเภท):
| ประเภท | ทำงานยังไง | เปรียบเทียบ |
|---|---|---|
| StaticMemoryBlock | ข้อความคงที่ (เช่น ชื่อ ที่อยู่) | เหมือนเขียนชื่อตัวเองติดไว้บนโต๊ะ |
| FactExtractionBlock | สกัดข้อเท็จจริงจากบทสนทนาอัตโนมัติ | เหมือนมีคนจดบันทึกให้ |
| VectorMemoryBlock | เก็บข้อความใน vector DB → ค้นหาด้วยความหมาย | เหมือนลิ้นชักที่จัดเรียงตามหมวดหมู่ |
จุดเด่นของ LlamaIndex: ใช้ Priority-based Truncation — แต่ละกล่องความจำมี "คะแนนความสำคัญ": Priority 0 → ไม่มีวันถูกลบ (เช่น ชื่อผู้ใช้ กฎพื้นฐาน) Priority 1, 2, 3... → ลบตามลำดับเมื่อความจำเต็ม (เช่น ข้อมูลเก่าที่ไม่ค่อยใช้)
เปรียบเทียบสั้นๆ:
| ด้าน | LangChain | LlamaIndex |
|---|---|---|
| แนวคิดหลัก | Middleware (พนักงานตรวจกรอง) | Priority (จัดลำดับความสำคัญ) |
| ความจำระยะสั้น | Checkpointer (PostgreSQL/RAM) | Memory class (SQLite) |
| ความจำระยะยาว | LangGraph Store (หมวดหมู่แบบ namespace) | Memory Blocks (หลายประเภท) |
| วิธีลดข้อมูล | ตัดทอน/สรุปด้วย middleware | ลบตามลำดับ priority |
| ข้อดี | ปรับแต่งยืดหยุ่น ใช้กับ LangGraph ได้ดี | มี fact extraction ในตัว จัด priority ชัดเจน |
| เหมาะกับ | โปรเจกต์ที่ต้องปรับแต่งเยอะ | โปรเจกต์ที่ต้องการระบบสำเร็จรูป |
สรุป: อะไรคือ "Best Practice" สำหรับความจำ AI ในปี 2026?
จากการวิจัยทั้งหมด สรุปได้ว่าระบบความจำ AI ที่ดีที่สุดในปี 2026 ควรมีอย่างน้อย 5 อย่างนี้:
- แยก "ตอบคำถาม" กับ "จัดการความจำ" — เหมือน Letta ที่แยก Primary Agent กับ Sleep-Time Agent → AI ตอบเร็วขึ้น ความจำดีขึ้น
- จัดระเบียบความจำเป็นหมวดหมู่ — ไม่ใช่ยัดทุกอย่างไว้ที่เดียว → ใช้ระบบไฟล์/หมวดหมู่เหมือน MemFS หรือ LangChain namespace
- จัดลำดับความสำคัญ — ข้อมูลสำคัญ (ชื่อ ความชอบ กฎ) ไม่มีวันถูกลบ → ข้อมูลเก่าไม่สำคัญค่อยๆ ลดความสำคัญลง เหมือน LlamaIndex priority
- เก็บข้อมูลดิบไว้ — อย่าสรุปย่อจนหมด → เก็บต้นฉบับไว้ (เหมือน MemMachine) แล้วใช้ระบบค้นหาที่ฉลาดแทน
- ให้ AI จัดการเองได้ — สร้างระบบที่ AI สามารถจัดระเบียบความจำตัวเองได้ (เหมือน Reflection Skill, Defragmentation Skill ของ Letta)
ถ้าจะสรุปในประโยคเดียว: ระบบความจำ AI ที่ดีที่สุด = เก็บของทุกอย่างไว้ (ไม่ทิ้ง) + จัดระเบียบเป็นหมวดหมู่ + ค้นหาด้วยวิธีหลายๆ แบบ + ให้ AI จัดการเองได้ + แยกการคุยกับการจำ
แหล่งอ้างอิง
Letta/MemGPT Sleep-Time Compute: https://www.letta.com/blog/sleep-time-compute Letta Context Constitution: https://www.letta.com/blog/context-constitution Letta Context Repositories (MemFS): https://www.letta.com/blog/context-repositories LangChain Memory Documentation: https://docs.langchain.com/oss/python/langchain/short-term-memory LlamaIndex Memory Module: https://developers.llamaindex.ai/python/framework/module_guides/deploying/agents/memory/ LangMem Library: https://github.com/langchain-ai/langmem MemGPT Original Paper: https://arxiv.org/abs/2310.08560