
คำนำ
เคยสงสัยไหมว่า AI ขนาดใหญ่อย่าง Claude หรือ ChatGPT จัดการข้อมูลมหาศาลยังไง โดยไม่ "เบลอ"? คำตอบไม่ใช่การซื้อความจำเพิ่ม แต่เป็นเทคนิคที่เรียกว่า Progressive Disclosure หรือ "โหลดเฉพาะที่จำเป็น" — แนวคิดเดียวกับที่นักออกแบบ UX ใช้กับแอปมือถือ แต่นำมาใช้กับระบบ AI แทน วันนี้เราจะมาเปิด 5 ระดับการโหลดข้อมูลของ AI ดูว่า Claude จัดการ context window ขนาด 200K tokens ยังไง และทำไม "การไม่อ่านทุกอย่าง" กลับทำให้ AI ตอบคำถามได้แม่นขึ้น
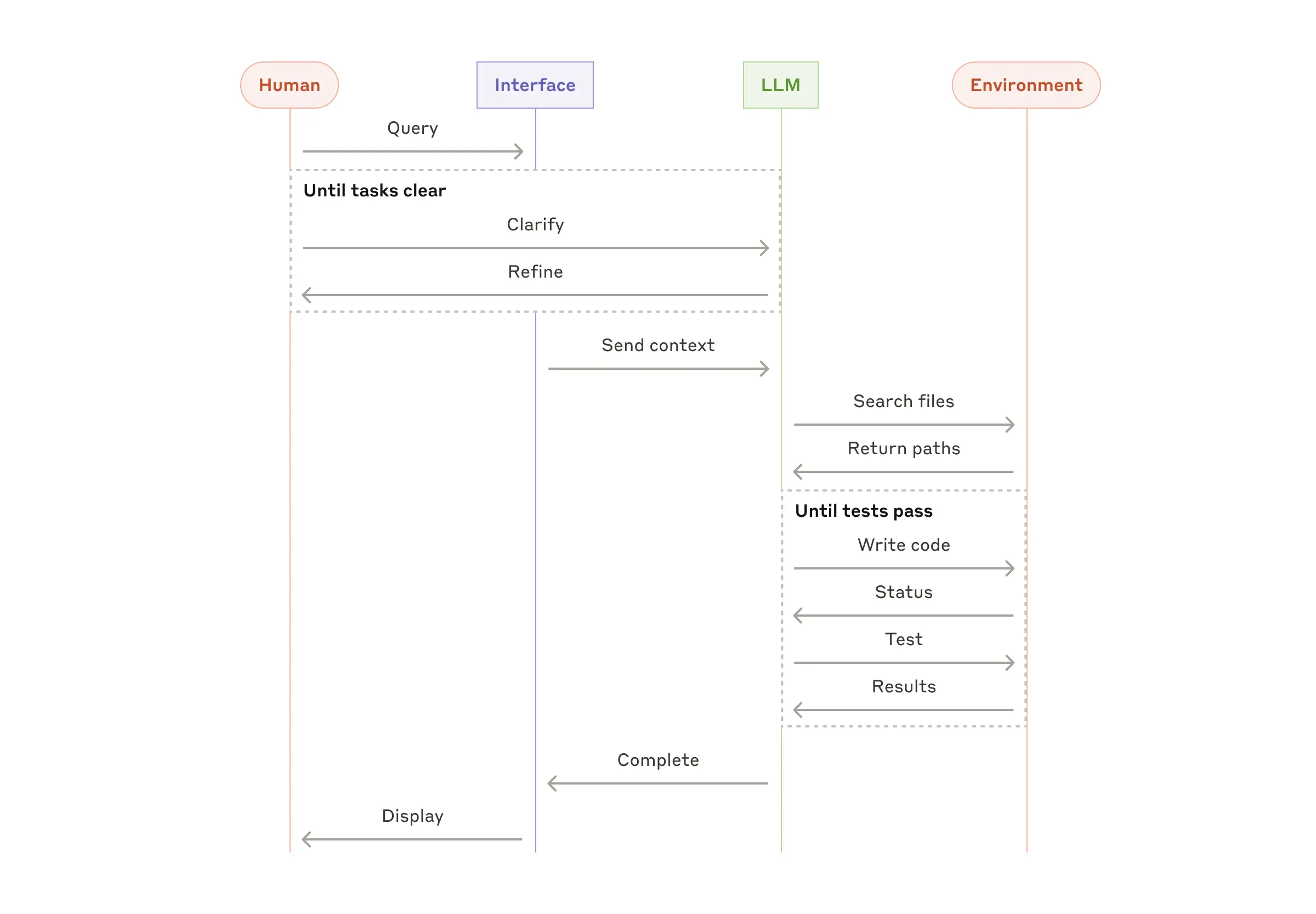
"อ่านทั้งหมด" ไม่ได้แปลว่า "เก่งขึ้น"
ก่อนจะเข้าเทคนิค เรามาเข้าใจปัญหากันก่อน สมมติคุณถาม AI ว่า "โปรเจกต์นี้ใช้ framework อะไร?" ถ้า AI ต้องอ่านไฟล์ทั้ง 500 ไฟล์ในโปรเจกต์ก่อนถึงจะตอบได้ มันจะช้ามาก แถมยัง "เบลอ" ด้วย เพราะข้อมูลเยอะเกินไป นี่คือสิ่งที่นักวิจัยเรียกว่า "Lost in the Middle" — เมื่อ context window มีข้อมูลเยอะเกิน AI จะใส่ใจข้อมูลต้นๆ และท้ายๆ แต่ลืมข้อมูลกลาง ยิ่งยัดเยอะ ยิ่งตอบผิด
ดังนั้น คีย์คือไม่ใช่ "อ่านให้มากที่สุด" แต่คือ "อ่านให้ถูกของ"
Progressive Disclosure คืออะไร?
Progressive Disclosure เป็นแนวคิดจากวงการ UX Design โดย Jakob Nielsen (ผู้เชี่ยวชาญด้าน usability ชื่อดัง) ตั้งแต่ปี 2006:
"แสดงเฉพาะข้อมูลที่สำคัญที่สุดก่อน แล้วค่อยเปิดเผยข้อมูลเพิ่มเติมเมื่อผู้ใช้ต้องการ"
ตัวอย่างในชีวิตจริง:
แอปเมนูอาหาร: แสดงชื่อ + รูปก่อน → กดเข้าไปค่อยเห็นรายละเอียดส่วนผสม แอปธนาคาร: แสดงยอดเงินคงเหลือก่อน → กดดูประวัติธุรกรรมทีหลัง หนังสือ: มีสารบัญอยู่ข้างหน้า → ไม่ต้องอ่านทั้งเล่มถึงจะรู้ว่าบทไหนเรื่องอะไร AI ก็ใช้หลักการเดียวกันนี้!
5 ระดับการโหลดข้อมูลของ AI
Level 0: โหลดตลอดเวลา (Always-Loaded)
เหมือนข้อมูลที่อยู่บนหน้าจอหลักของมือถือ — AI จะเห็นข้อมูลนี้ทุกครั้งที่ตอบคำถาม
สิ่งที่อยู่ในระดับนี้:
กฎพื้นฐานของ AI (เช่น "ตอบเป็นภาษาไทย")
ข้อมูลสำคัญที่ต้องใช้ทุก task (เช่น สไตล์การทำงานของโปรเจกต์)
ข้อจำกัด: Claude Code แนะนำว่าข้อมูลส่วนนี้ไม่ควรเกิน 200 บรรทัด — เกินนี้ AI จะเริ่ม "ไม่สนใจ" คำสั่ง
ตัวอย่าง: Claude ใช้ไฟล์ CLAUDE.md เป็นข้อมูล Level 0 — โหลดทุกครั้งที่เริ่ม session ใหม่
Level 1: โหลดตามเงื่อนไข (Conditionally-Loaded)
เหมือนแอปที่แสดงข้อมูลต่างกันตามหน้าที่คุณอยู่ — AI โหลดข้อมูลบางอย่างเฉพาะเมื่อทำงานเกี่ยวข้อง
วิธีทำงาน: AI มีกฎอยู่ว่า "ถ้ากำลังแก้ไขไฟล์ในโฟลเดอร์ src/api/ → โหลดกฎเกี่ยวกับ API validation มาด้วย"
ตัวอย่าง: คุณมีโปรเจกต์ใหญ่ที่มีทั้ง frontend และ backend — เมื่อ AI แก้ไฟล์ frontend มันจะโหลดกฎ frontend เท่านั้น ไม่ต้องโหลดกฎ backend มารวน
ประโยชน์: ประหยัดพื้นที่ความจำ แถม AI มีสมาธิกับงานที่ทำอยู่มากขึ้น
Level 2: โหลดเมื่อต้องการ (On-Demand)
เหมือนเวลาคุณกด "ดูเพิ่มเติม" ในแอป — AI เลือกเอง ว่าจะโหลดข้อมูลไหนจากคำอธิบายสั้นๆ วิธีทำงาน: AI เห็นแค่ "ชื่อ + คำอธิบายสั้น" ของ skill ต่างๆ เมื่อตัดสินใจว่า skill ไหนเกี่ยวข้อง ค่อยโหลดเนื้อหาเต็ม ตัวอย่าง: Claude Code มี Skills หลายอัน (เช่น ทำ PowerPoint, วิเคราะห์ PDF, จัดรูปแบบ Excel) — AI จะโหลดเฉพาะ skill ที่เกี่ยวข้องกับคำถาม ไม่ได้โหลดหมดทุกอัน
Level 3: โหลดจากโฟลเดอร์ย่อย (Lazy-Loaded Subdirectories)
เหมือนโฟลเดอร์ย่อยในเว็บไซต์ — AI จะอ่านข้อมูลในโฟลเดอร์นั้นก็ต่อเมื่อมันเข้าไปทำงานในโฟลเดอร์นั้นจริงๆ ตัวอย่าง: ในโปรเจกต์ monorepo ที่มีหลาย service (auth, payment, notification) — แต่ละ service มีคำแนะนำเฉพาะของตัวเอง AI จะอ่านคำแนะนำของ service นั้นก็ต่อเมื่อต้องแก้ไขไฟล์ในนั้น
Level 4: ค้นหาจากภายนอก (External Retrieval)
เหมือนการ Google — AI ต้อง "ค้นหา" ข้อมูลจากแหล่งภายนอก ผ่านเครื่องมือค้นหา ตัวอย่าง: ค้นหาจาก vector database, ค้นหาจากเว็บ, หรือค้นหาจาก archival memory ใช้พลังงานน้อยสุด (ไม่ต้องโหลดอะไรไว้ล่วงหน้า) แต่ ช้าที่สุด (ต้องค้นหาก่อนถึงจะได้คำตอบ)
Claude จัดการ Context Window ยังไง? 4 เลเยอร์ที่น่าสนใจ
Claude (โดย Anthropic) มีระบบจัดการข้อมูล 4 ชั้นที่ทำงานร่วมกัน:
เลเยอร์ 1: Prompt Caching (แคชข้อมูลเก่า)
เหมือนแคชในเบราว์เซอร์ — ข้อมูลที่ใช้ซ้ำบ่อยๆ จะถูกเก็บไว้ ไม่ต้องโหลดใหม่
ทำงานยังไง: ใส่ cache_control ในข้อความ → Anthropic จะแคชข้อมูลนั้นไว้ 5 นาที
ประหยัดขนาดไหน: Cache read ลดค่าใช้จ่าย 90% เทียบกับการโหลดใหม่ทั้งหมด
ใช้กับอะไร: System prompt, คำจำกัดความของเครื่องมือ, ข้อมูลฐานความรู้ที่ไม่ค่อยเปลี่ยน
ตัวอย่างในชีวิตจริง: เหมือนเวลาคุณเข้าเว็บไซต์เดิมซ้ำ — รูปภาพและ CSS ไม่ต้องโหลดใหม่ เพราะเบราว์เซอร์แคชไว้แล้ว
เลเยอร์ 2: Context Editing (ลบของไม่จำเป็น)
เหมือนการเก็บกวาดโต๊ะทำงาน — ลบข้อมูลที่ใช้เสร็จแล้วออกจากความจำ ทำงานยังไง: หลังจากใช้เครื่องมือเสร็จ → ลบผลลัพธ์ชั่วคราวออกจาก context ตัวอย่าง: สมมติ AI ใช้เครื่องมือ 20 อันในการแก้บั๊ก → ลบ 18 อันเก่า เหลือเฉพาะ 2 อันล่าสุด + สรุปผล
เลเยอร์ 3: Memory Tool (ข้อมูลถาวร)
เหมือนสมุดบันทึก — AI สามารถจดบันทึกข้อมูลสำคัญไว้ใช้ข้ามการสนทนา ทำงานยังไง: เก็บเป็น key-value → AI ใช้เครื่องมือบันทึก/อ่าน/ลบ ได้เอง ใช้เก็บอะไร: ความชอบของผู้ใช้, สถานะโปรเจกต์, ข้อเท็จจริงที่ต้องใช้ซ้ำ
เลเยอร์ 4: Compaction (บีบอัดเมื่อเต็ม)
เหมือนการสรุปย่อ — เมื่อข้อมูลใกล้จะเต็มความจำ AI จะสรุปข้อมูลเก่าให้สั้นลง ทำงานยังไง: เมื่อข้อมูลถึง 150K tokens (จาก 200K) → สร้างสรุปย่อ → ลบข้อมูลเก่า → ทำงานต่อจากสรุป สิ่งสำคัญที่ต้องรู้: Compaction เป็นการจัดการพื้นที่ ไม่ใช่การ "จดจำ" — ดังนั้นข้อมูลสำคัญควรถูกบันทึกลง Memory Tool ก่อนจะถูกบีบอัด
รูปแบบที่ใช้ได้จริง: 5 Pattern ที่ AI ยักษ์ใหญ่ใช้
Pattern 1: สารบัญ → รายละเอียด (Index-then-Detail)
AI มี "สารบัญ" อยู่ในความจำตลอดเวลา → อ่านรายละเอียดเฉพาะเมื่อต้องการ
เหมือนหนังสือ: รู้ว่าบท 3 พูดเรื่องอะไรจากสารบัญ ไม่ต้องอ่านทั้งเล่ม
Pattern 2: เลือกตามขอบเขต (Scope-then-Load)
AI โหลดข้อมูลเฉพาะเมื่อทำงานในขอบเขตที่เกี่ยวข้อง
เหมือนหมอ: หมอกระดูกไม่ต้องรู้เรื่องตา หมอตาไม่ต้องรู้เรื่องกระดูก — แต่ละคนมีความรู้เฉพาะทาง
Pattern 3: ตัดสินใจเองว่าจะโหลดอะไร (Relevance-then-Retrieve)
AI เห็นแค่ metadata (ชื่อ + คำอธิบายสั้น) แล้วตัดสินใจเองว่าจะโหลดอันไหน
เหมือนเลือกหนังสือในร้าน: อ่านชื่อ + ปกหลังก่อน แล้วค่อยเลือกว่าจะเปิดอ่านเล่มไหน
Pattern 4: บีบอัดแล้วทำต่อ (Compress-then-Continue)
เมื่อความจำใกล้เต็ม → สรุปของเก่า → ทำงานต่อ
เหมือนการจดโน้ต: พอสมุดเต็ม → สรุปย่อสิ่งสำคัญ → เขียนต่อในสมุดเล่มใหม่
Pattern 5: มอบหมายงานย่อย (Delegate-then-Synthesize)
AI หลักมอบหมายงานให้ AI ย่อยทำในพื้นที่ความจำของตัวเอง → รับแค่ผลลัพธ์สรุปกลับมา
เหมือนผู้จัดการ: มอบหมายงานให้ทีม → รับแค่รายงานสรุป ไม่ต้องรู้รายละเอียดทุกอย่าง
ทำไม 2 ระดับคือดีที่สุด?
Jakob Nielsen (guru ด้าน UX) แนะนำว่า Progressive Disclosure ไม่ควรเกิน 2 ระดับ:
| ระดับ | คำอธิบาย | AI ทำอย่างไร |
|---|---|---|
| ระดับ 1 (โหลดตลอด) | ข้อมูลสำคัญที่ต้องเห็นเสมอ | สารบัญ, กฎพื้นฐาน, ข้อมูลประจำตัว |
| ระดับ 2 (โหลดเมื่อต้องการ) | รายละเอียดที่ดึงมาเมื่อเกี่ยวข้อง | เอกสารเฉพาะทาง, ประวัติการสนทนา, ข้อมูลเพิ่มเติม |
ถ้ามากกว่า 2 ระดับ AI จะ "สับสน" — ไม่รู้ว่าข้อมูลที่ต้องการอยู่ระดับไหน เสียเวลาค้นหาโดยไม่จำเป็น
สรุป: สิ่งที่เราเรียนรู้
Progressive Disclosure สอนเราว่า: การจัดการข้อมูลที่ดีไม่ใช่การเก็บทุกอย่างไว้ในหัว แต่เป็นการรู้ว่าอะไรสำคัญตอนนี้ และอะไรสามารถหยิบมาใช้ได้เมื่อต้องการ Claude ใช้ 4 เลเยอร์ (caching, editing, memory, compaction) ทำงานร่วมกัน 5 pattern (index-detail, scope-load, relevance-retrieve, compress-continue, delegate-synthesize) เพื่อให้ AI ตอบคำถามได้แม่นยำและรวดเร็ว โดยไม่เปลืองพลัง — หลักการนี้ไม่ได้ใช้แค่กับ AI แต่ใช้ได้กับการจัดการความรู้ของเราทุกคนเช่นกัน: จัดระเบียบข้อมูลเป็น "สารบัญ + รายละเอียด" แล้วคุณจะทำงานได้เร็วขึ้นโดยไม่สูญเสียความแม่นยำ
แหล่งอ้างอิง
Anthropic — Building Effective Agents (ธันวาคม 2024): https://www.anthropic.com/engineering/building-effective-agents Claude Code — Best Practices: https://code.claude.com/docs/en/best-practices Claude Code — How Claude Remembers Your Project: https://code.claude.com/docs/en/store-instructions-and-memories Claude API — Prompt Caching: https://platform.claude.com/docs/en/build-with-claude/prompt-caching Claude API — Compaction: https://platform.claude.com/docs/en/build-with-claude/compaction Jakob Nielsen — Progressive Disclosure (2006): https://www.nngroup.com/articles/progressive-disclosure/ Lilian Weng — LLM Powered Autonomous Agents: https://lilianweng.github.io/posts/2023-06-23-agent/